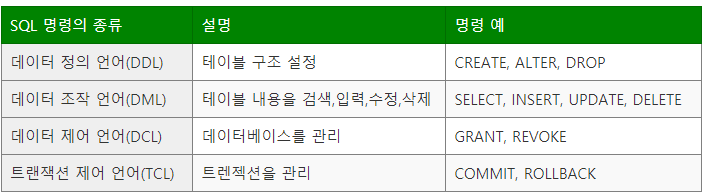
무결성(CONSTRAINT) : COLUMN을 지정하는 성질(설정)
종류
Primary Key : 기본키. 중복을 허용하지 않는다. NULL을 허용하지 않는다. 예시) ID, 주민번호
Unique Key : 고유키. 중복을 허용하지 않는다. NULL을 허용한다. 예시) e-mail
Foreign Key : 외래키. JOIN(테이블과 테이블의 연결)이 목적. NULL을 허용한다.
외래키로 지정된 컬럼은 연결된 테이블에서 PK나 UK로 설정되어 있어야 한다.
CHECK : 범위를 지정. 지정된 값 외에 사용할 수 없다. 중복을 허용한다. NULL을 허용한다.
NOT NULL : 중복을 허용한다. NULL을 허용하지 않는다.
NOT NULL : 데이터 삽입 시 NULL을 허용하지 않는다.
형식
CREATE TABLE 테이블명(
컬럼명 데이터형식(크기) NOT NULL,
);
참고
행 삽입 시 NOT NULL 지정 컬럼에 데이터를 삽입하지 않으면 경우 에러가 발생한다.
예시
-- 테이블 생성
CREATE TABLE TB_TEST08(
COL1 VARCHAR2(10) NOT NULL,
COL2 VARCHAR2(20)
);
-- 데이터 삽입
INSERT INTO TB_TEST08(COL1, COL2)
VALUES ('AAA','111');
INSERT INTO TB_TEST08(COL1)
VALUES ('BBB');
INSERT INTO TB_TEST08(COL2)
VALUES ('222'); -- 오류발생 COL1 NOT NULL
CASCADE CONSTRAINTS : 무결성 제약조건까지 모두 삭제
형식
DROP TABLE 테이블명
CASCADE CONSTRAINTS;
참조
예시처럼 똑같이 진행 시 이미 테이블이 생성되어 있어서 에러가 발생할 것입니다.
테이블 생성 시마다 아래 예시를 실행해주어야 에러가 발생하지 않습니다.
예시
DROP TABLE TB_TEST08
CASCADE CONSTRAINTS;
Primary Key(기본키) : 중복금지 + NOT NULL
형식
1. CREATE TABLE 테이블명(
컬럼명 데이터형식(크기) PRIMARY KEY
);
2. CREATE TABLE 테이블명(
컬럼명 데이터형식(크기) CONSTRAINT Key ID PRIMARY KEY
);
3. CREATE TABLE 테이블명(
컬럼명1 데이터형식(크기),
컬럼명2 데이터형식(크기)
CONSTRAINT Key ID PRIMARY KEY(컬럼명1, 컬럼명2)
);
참고
1 형식으로 만들 수 있지만, Key ID 지정하지 않았을 경우 지정한 PRIMARY KEY만 삭제를 하지 못하게 된다.
지정한 PRIMARY KEY 삭제 시 Key ID 필요!
3 형식으로 생성 시 2개 이상의 컬럼을 PRIMARY KEY로 지정할 수 있다.
행 삽입 시 PRIMARY KEY로 지정 컬럼에 데이터를 삽입하지 않으면 경우 에러가 발생한다.
행 삽입 시 PRIMARY KEY로 지정 컬럼에 데이터를 중복 삽입할 경우 에러가 발생한다.
예시
CREATE TABLE TB_TEST08(
-- PK_COL VARCHAR2(10) PRIMARY KEY -- 가능하지만
PK_COL VARCHAR2(10) CONSTRAINT PK_TEST_01 PRIMARY KEY, -- PK_TEST_01 : Primary Key ID 지정
COL1 VARCHAR2(20),
COL2 VARCHAR2(20)
);
INSERT INTO TB_TEST08(PK_COL, COL1, COL2)
VALUES('AAA','aaa','111');
INSERT INTO TB_TEST08(PK_COL)
-- VALUES('AAA'); -- 중복 허용X , 에러발생.
VALUES('BBB');
-- INSERT INTO TB_TEST08(PK_COL, COL1, COL2)
-- VALUES('','aaa','111'); -- '' = NULL , 에러발생
-- 에러 only one primary key
/*
CREATE TABLE TB_TEST08(
PK_COL1 VARCHAR2(10) CONSTRAINT PK_TEST_01 PRIMARY KEY,
PK_COL2 VARCHAR2(10) CONSTRAINT PK_TEST_02 PRIMARY KEY,
COL1 VARCHAR2(20),
COL2 VARCHAR2(20)
);
*/
-- 프라이머리키 2개 이상 생성 방법
CREATE TABLE TB_TEST08(
PK_COL VARCHAR2(10),
COL1 VARCHAR2(20),
COL2 VARCHAR2(20),
CONSTRAINT PK_TEST_01 PRIMARY KEY(PK_COL, COL1)
);
무결성이 없는 테이블 생성 후 무결성 변경하는 방법
형식
1. ALTER TABLE 테이블명
ADD PRIMARY KEY (컬럼명1, 컬럼명2..);
2. ALTER TABLE 테이블명
ADD CONSTRAINT Key ID명
PRIMARY KEY(컬럼명);
참조
진행 전 무결성이 없는 테이블이 생성되어 있어야 합니다.
예시
-- 무결성 없는 테이블 생성
CREATE TABLE TB_TEST08(
PK_COL1 VARCHAR2(10),
COL1 VARCHAR2(20),
COL2 VARCHAR2(20)
);
-- 테이블 만든 후 나중에 무결성 변경가능
-- 1형식
ALTER TABLE TB_TEST08
ADD PRIMARY KEY (PK_COL);
-- 2형식
ALTER TABLE TB_TEST08
ADD CONSTRAINT PK_TEST_01
PRIMARY KEY(PK_COL1);
무결성 삭제 방법
형식
1. ALTER TABLE 테이블명
DROP PRIMARY KEY;
2. ALTER TABLE 테이블명
DROP CONSTRAINT Key ID명 ;
참조
1 형식으로 키 추가를 했다면 1 형식으로만 삭제해야 한다.
1 형식은 지정한 Key ID값을 삭제할 수 없고, 전체 키값이 삭제된다.
2 형식으로 키 추가했을 경우 2가지 경우 다 삭제 가능하다
예시
-- 1형식
ALTER TABLE TB_TEST08 DROP PRIMARY KEY;
-- 2형식
ALTER TABLE TB_TEST08
DROP CONSTRAINT PK_TEST_01;
Unique(고유키) : 중복된 값은 입력 불가. NULL은 허용
형식
1. CREATE TABLE 테이블명(
컬럼명 데이터형식(크기) UNIQUE
);
2. CREATE TABLE 테이블명(
컬럼명 데이터 형식(크기) CONSTRAINT Key ID UNIQUE
);
참조
기본키와 마찬가지로 1 형식으로 만들 수 있지만, Key ID 지정하지 않았을 경우 지정한 UNIQUE KEY만 삭제를 하지 못하게 된다.
지정한 UNIQUE 삭제 시 Key ID 필요!
예시
CREATE TABLE TB_TEST08(
-- UK_COL VARCHAR2 UNIQUE -- 가능
UK_COL VARCHAR2(10) CONSTRAINT UK_TEST_01 UNIQUE,
COL1 VARCHAR2(20),
COL2 VARCHAR2(20)
);
INSERT INTO TB_TEST08(UK_COL, COL1, COL2)
VALUES('','aaa','111'); -- ''가능하다 (프라이머리키와 차이점)
INSERT INTO TB_TEST08(COL1, COL2)
VALUES('aaa','111'); -- ''가능하다 (프라이머리키와 차이점)
FOREIGN KEY(외래키) : 대상 테이블에서 pk, uk로 설정되어 있어야 한다. NULL 값을 허용. 중복 허용
형식
CREATE TABLE 테이블명(
DEPARTMENT_ID VARCHAR2(10),
CONSTRAINT Key ID FOREIGN KEY(컬럼명)
REFERENCES 대상테이블명(대상테이블의 기본키(OR 고유키) 컬럼명)
);
참조
외래키 테이블 생성 전 대상테이블이 생성되어 있어야 한다.
외래키에 데이터를 넣기 전 대상테이블의 기본키에 데이터가 들어가 있어야 한다.
외래키의 크기는 대상테이블의 기본키(OR 고유키)보다 크기가 같거나 커야 한다.
대상테이블의 기본키와 외래키의 컬럼명을 달라도 된다.
외래키 데이터는 아무 값이나 넣으면 안 된다.(대상 테이블의 기본키의 데이터와 같아야 한다.)
예시
-- 대상 테이블 생성
CREATE TABLE TB_DEPT(
DEPARTMENT_ID VARCHAR2(10),
DEPARTMENT_NAME VARCHAR2(20),
LOCATION_ID NUMBER,
CONSTRAINT PK_DEPT_TEST PRIMARY KEY(DEPARTMENT_ID) -- PRIMARY KEY이거나 Unique여야 한다.
);
-- 데이터 추가
INSERT INTO TB_DEPT(DEPARTMENT_ID, DEPARTMENT_NAME, LOCATION_ID)
VALUES('10', '기획부', '120');
INSERT INTO TB_DEPT(DEPARTMENT_ID, DEPARTMENT_NAME, LOCATION_ID)
VALUES('20', '관리부', '150');
INSERT INTO TB_DEPT(DEPARTMENT_ID, DEPARTMENT_NAME, LOCATION_ID)
VALUES('30', '개발부', '180');
-- 기준 테이블 생성
CREATE TABLE TB_EMP(
EMPNO VARCHAR2(10),
ENAME VARCHAR2(20),
DEPARTMENT_ID VARCHAR2(10), -- 외래키의 크기는 대상테이블의 기본키(OR 고유키)보다 크기가 같거나 커야 한다.
CONSTRAINT FK_EMP_TEST FOREIGN KEY(DEPARTMENT_ID)
REFERENCES TB_DEPT(DEPARTMENT_ID) -- 기본키와 외래키의 컬럼명을 달라도 된다.
); -- 이제 JOIN이 가능해 진다.
-- 데이터 추가
INSERT INTO TB_EMP(EMPNO, ENAME, DEPARTMENT_ID)
VALUES('100', '일', '20'); -- DEPARTMENT_ID 아무값이나 넣으면 안된다.(대상 테이블의 기본키값과 같아야한다.)
INSERT INTO TB_EMP(EMPNO, ENAME, DEPARTMENT_ID)
VALUES('101', '이', '10');
INSERT INTO TB_EMP(EMPNO, ENAME, DEPARTMENT_ID)
VALUES('102', '삼', '30');
INSERT INTO TB_EMP(EMPNO, ENAME, DEPARTMENT_ID)
VALUES('103', '사', ''); -- 외래키는 NULL값 허용한다.
-- INNER JOIN
SELECT e.empno, e.ename, d.department_id, d.department_name
FROM tb_emp e, tb_dept d
WHERE e.department_id = d.department_id;
CHECK : 범위 값을 설정하거나 지정된 값만 넣을 수 있다. NULL 허용, 중복 허용
형식
CREATE TABLE TB_CHECK(
컬럼명1 데이터형식(크기),
컬럼명2 데이터형식(크기),
CONSTRAINT Key ID ( 컬럼명1 IN('지정값1', '지정값2', '지정값3') ),
CONSTRAINT Key ID ( 컬럼명2 > 범위1 AND COL2 <= 범위2)
);
예시
-- 테이블 생성
CREATE TABLE TB_CHECK(
COL1 VARCHAR2(10),
COL2 VARCHAR2(20),
CONSTRAINT CHK_01 CHECK( COL1 IN('사과', '배', '바나나') ), -- 사과, 배, 바나나와 NULL
CONSTRAINT CHK_02 CHECK( COL2 > 0 AND COL2 <= 100) -- 1~100 숫자와 NULL
);
-- 데이터 삽입
INSERT INTO tb_check(COL1,COL2)
VALUES('사과', 50);
INSERT INTO tb_check(COL1,COL2)
VALUES('귤', 50); -- 불가능 에러
INSERT INTO tb_check(COL1,COL2)
VALUES('', 50);
INSERT INTO tb_check(COL1,COL2)
VALUES('', 101); -- 불가능 에러