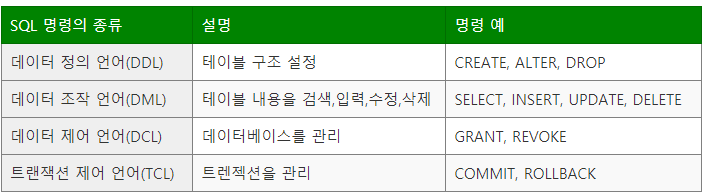
정의 : 데이터 베이스를 관라하고 조작하는 질의언어 목적 : 유무형 데이터를 데이터베이스 내 규격화된 장소에 저장하고 분석과 통계 작업으로 가치있는 정보를 얻기 위함이다.
데이터
유무형의 형태를 구성하는 요소 하나이상의 데이터가 모여 의미 있는 형태를 만든다.
필드 (== 컬럼)
속성값을 부여한 데이터 형식 : 수치, 문자, 날짜, 메모등이 있으며, 형식에 따라 고정길이 및 초기 설정값을 갖는다. 속성값 예시
고정 문자열 7자리, 공백 허용 안함, 기본키 적용 CHAR(7) NOT NULL 1
레코드
연관된 필드의 모음 한개의 ROW값에 연관된 필드의 모음
테이블
연관된 레코드의 모음
데이터베이스(Database:DB)
업무나 시스템 단위로 연관된 테이블의 모음
데이터베이스 관리 시스템(DBMS)
복잡한 SQL명령어를 사용하지 않고 프로그램을 통해 데이터 베이스를 효과적으로 조작할 수 있게 한다. 여러 사용자가 데이터베이스 서버에 직접 접근하지 않고 DBMS의 관리 프로그램으로 간접 제어 가능 데이터 정의, 조작(삽입,삭제,변경 및 검색), 제어(일관성,무결성,보안)
데이터베이스 시스템 : DB+DBMS+응용프로그램
데이터 정의 언어(DDL)
CREATE : 테이블 생성 ALTER : 테이블 구조 변경 DROP : 테이블 삭제
데이터 조작 언어(DML)
SELECT : 테이블에 데이터 검색 INSERT : 테이블에 데이터 입력 UPDATE : 테이블에 데이터 수정 DELETE : 테이블에 데이터 삭제
데이터 제어 언어(DCL)
GRANT : 계정에 권한 부여 REVOKE : 계정에 권한
트랜잭션 제어 언어(TCL)
COMMIT : 데이터베이스 작업 중 수정한 내용을 반영 ROLLBACK : 수정한 내용을 취소하고 이전 상태로 돌아가기
GROUP BY 를 보강하기 위해서 나온 함수 SELECT 절에서만 사용 가능 그룹함수를 사용하려면 GROUP BY를 사용해야 하지만, OVER()를 사용하면 GROUP BY를 하지 않아도 된다. PARTITION BY(그룹핑) 한 데이터를 정렬해서 뽑는다.
예시
-- hr 스키마
SELECT department_id, COUNT(*)OVER()
FROM employees;
PARTITION BY : 특정 컬럼 기준으로 그룹을 만든다. ★★★★★
형식
SELECT 컬럼명, 그룹함수() OVER ( PARTITION BY 그룹컬럼명) FROM 테이블명;
참고
SELECT 절 안에 GROUP BY
예시
SELECT department_id, first_name, salary,
-- department_id 묶어서 카운트로 씌워라
COUNT(*)OVER(PARTITION BY department_id)
FROM employees;
분석함수(순위함수)
특정 집합 내에서 결과 건수의 변화없이 해당 집합안에서 합계 및 카운트 등을 계산할 수 있는 함수이다.
RANK() : 중복 순번 후 순위만큼 이동한 순번 구하기
형식
1. RANK()OVER(ORDER BY 정렬컬럼명) AS RANK
2. RANK() OVER (PARTITION BY 그룹컬럼명 ORDER BY 정렬컬럼명) AS RANK
참고
1형식은 정렬컬럼명으로 정렬해 같은 값이면 중복순위를 부여하고 그 이후는 해당 순위만큼 이동한 순위를 구한다.
2형식은 그룹컬럼으로 그룹을 만들고 정렬컬럼명으로 정렬해 같은 값이면 중복순위를 부여하고 그 이후는 해당 순위만큼 이동한 순위를 구한다.
예시 : 1 2 3 3 5 6
-- 1형식
SELECT employee_id, first_name, salary,department_id,
RANK()OVER(ORDER BY salary DESC) AS RANK
FROM employees;
-- 2형식
SELECT employee_id, first_name, salary,department_id,
RANK()OVER(PARTITION BY department_id ORDER BY salary DESC) AS RANK
FROM employees;
DENSE_RANK() : 중복 순번 후 순차 순번 구하기
형식
1. DENSE_RANK()OVER(ORDER BY정렬컬럼명) AS RANK
2. DENSE_RANK() OVER (PARTITION BY 그룹컬럼명 ORDER BY 정렬컬럼명) AS RANK
참고
1형식은정렬컬럼명으로 정렬해 같은 값이면 중복순위를 부여하고 그 이후는 순차적인 순위를 구한다.
2형식은 그룹컬럼으로 그룹을 만들고정렬컬럼명으로 정렬해 같은 값이면 중복순위를 부여하고 그 이후는 순차적인 순위를 구한다.
예시 : 1 2 3 3 4 5
-- 1형식
SELECT employee_id, first_name, salary,department_id,
DENSE_RANK()OVER(ORDER BY salary DESC) AS RANK
FROM employees;
-- 2형식
SELECT employee_id, first_name, salary,department_id,
DENSE_RANK()OVER(PARTITION BY department_id ORDER BY salary DESC) AS RANK
FROM employees;
ROW_NUMBER() : 중복없는 순번 구하기
형식
1. ROW_NUMBER()OVER(ORDER BY정렬컬럼명) AS RANK
2. ROW_NUMBER() OVER (PARTITION BY 그룹컬럼명 ORDER BY 정렬컬럼명) AS RANK
참고
1형식은정렬컬럼명으로 정렬해 중복 없는 순번을 구한다.
2형식은 그룹컬럼으로 그룹을 만들고정렬컬럼명으로 정렬해 중복 없는 순번을 구한다.
예시 : 1 2 3 4 5 6
-- 1형식
SELECT employee_id, first_name, salary,department_id,
ROW_NUMBER()OVER(ORDER BY salary DESC) AS RANK
FROM employees;
-- 2형식
SELECT employee_id, first_name, salary,department_id,
ROW_NUMBER()OVER(PARTITION BY department_id ORDER BY salary DESC) AS RANK
FROM employees;
ROWNUM : 조회한 행 번호 구하기 ★★★★★
형식
SELECT ROWNUM, 컬럼명 FROM 테이블명;
참고
게시판에서 글들을 한페이지에 글을 1~20번까지 불러올 때 사용한다.
테이블 전체 컬럼을 출력하고 싶을 땐 FROM 테이블명에 별명을 사용해주고 SELECT 절에 별명.*해주면 된다.
예시 : 1 2 3 4 5 6
-- ROWNUM의 1~10까지 출력하라
SELECT ROWNUM, employee_id, first_name
FROM employees
WHERE ROWNUM <= 10; -- ROWNUM이 10보다크고 20보다 작은경우를 구해보자.
-- WHERE ROWNUM > 10 AND ROWNUM <= 20; -- 실행이 되지 않는다.
-- 급여의 순위를 구한다
-- 1. 정렬 많음 -> 적음
-- 2. 번호 지정 1 2 3 4
-- 3. 범위 지정 1~10 11~20
SELECT RNUM, employee_id, first_name, salary
FROM
(SELECT ROWNUM AS RNUM, employee_id, first_name, salary
FROM
(SELECT employee_id, first_name, salary -- 급여순위
FROM employees
ORDER BY salary DESC)
)
WHERE RNUM >= 1 AND RNUM <= 10;
비교할 컬럼을 지정하고 그 컬럼 안의 ROW값을 설정하여 ROW값일 경우 출력문자를 출력하는 방법이다.
형식
SELECT 컬럼명, 컬럼명,
CASE 비교컬럼명
WHEN 검색값 THEN 출력문자
WHEN 검색값 THEN 출력문자
ELSE defalut값의 출력문자
END
FROM 테이블명;
예시
-- hr 스키마
SELECT employee_id, first_name, phone_number,
CASE SUBSTR(phone_number,1,3) -- 지역번호
WHEN '515' THEN '서울'
WHEN '590' THEN '부산'
WHEN '650' THEN '공주'
ELSE '기타'
END
FROM employees;
QUERY 안의 QUERY 한 개의 행(ROW, RECORD, 한 사람에 해당하는 데이터)에서 결과 값이 반환되는 QUERY
서브 칼럼이 *이 아닌 이상 서브 칼럼이랑 외부 칼럼이 같아야 한다. 사용 : 테이블이 있는데 걸러내서 산출하고 싶을 때
현재까지 배운 종류
- SELECT 단일 ROW 단일 COLUMN (산출되는 데이터는 한 개, 컬럼도 한 개) - FROM 다중 ROW 다중 COLUMN - WHERE 다중 ROW 다중 COLUMN(제일 많이 사용)
SELECT절
-- hr 스키마
SELECT employee_id, first_name,
(SELECT first_name -- 단일 COLUMN
FROM employees
WHERE employee_id = 100) -- 단일 ROW
FROM employees;
SELECT first_name,
(SELECT SUM(salary) FROM employees),
(SELECT AVG(salary) FROM employees)
FROM employees;
-- 평균월급에 내 월급이 얼마인지 비교
SELECT first_name, salary, (SELECT AVG(salary) FROM employees)
FROM employees
WHERE department_id = 30;
FROM절
-- 100번 부서에 있는 사람만 걸러내서 테이블을 만듯 것
-- 그테이블의 값을 받아낸 것
-- 별칭으로도 내보낼 수 있다.
SELECT EMPNO, NAME ,SAL
FROM ( SELECT employee_id EMPNO, first_name NAME ,salary SAL
FROM employees
WHERE department_id = 100)
WHERE SAL > 8000;
-- 부서번호가 50번, 급여가 6000이상인 사원
SELECT employee_id, first_name, last_name, salary
FROM ( SELECT *
FROM employees
WHERE department_id = 50)
WHERE salary >= 6000;
-- 업무별 급여의 합계, 인원수, 사원명, 월급
SELECT e.employee_id, e.first_name,j.급여합계, j.인원수
FROM employees e, (SELECT job_id, SUM(salary) 급여합계, COUNT(*) 인원수
FROM employees
GROUP BY job_id) j;
WHERE절
-- 평균 급여보다 많은 사원
SELECT employee_id, first_name, salary
FROM employees
WHERE salary > (SELECT AVG(salary)
FROM employees);
-- 부서 90인 사원의 업무명
SELECT job_id, first_name, department_id
FROM employees
WHERE job_id IN (SELECT job_id
FROM employees
WHERE department_id = 90);
-- 부서별로 가장 급여를 적게 받는 사월의 급여와 같은 급여를 받는 사원
SELECT first_name, salary, department_id
FROM employees
WHERE salary IN (SELECT MIN(salary)
FROM employees
GROUP BY department_id);
-- 부서별로 가장 급여를 적게 받는 사원과 급여
-- GROUP으로만 못구할 때 서브쿼리 사용
SELECT first_name, employee_id, salary, department_id
FROM employees
WHERE (department_id, salary) IN (SELECT department_id, MIN(salary)
FROM employees
GROUP BY department_id);
두 개 이상의 테이블을 연결해서 데이터를 검색하는 방법 보통 두개이상의 행(ROW)들의 공통된 값 기본키(PRIMARY KEY), 외래키를 사용해서 JOIN 한다. 현재 테이블의 외래키(model F)를 통해 상대 테이블의 기본키(model P & U)에 연결 목적 : 현재 테이블에 없는 값을 상대 테이블의 정보(칼럼)에서 산출하기 위한 것. 기본키(Primary key) : 테이블에서 중복되지 않는 키 (model P) 외래키(Foreign key) : 다른 테이블에서 기본키이거나 고유키인 경우가 많다. (model F)
JOIN 종류
inner join = 교집합 ★★★★★ (basic)
full outer join = 합집합
cross join outer join ★★★ left right self join ★★★★★
형식
ANSI문법
SELECT 검색컬럼명
FROM 테이블명1 별명1 JOIN 테이블명2 별명2
ON 별명1.외래키 = 별명2.기본키(OR 고유키);
오라클문법
SELECT 검색컬럼명
FROM 테이블명1 별명1, 테이블명2 별명2
WHERE 별명1.외래키 = 별명2.기본키(OR 고유키);
inner join : 기준테이블과 대상 테이블에 매칭하는 필드값이 있는 경우에 검색한다.
참고
2개이상의 테이블도 JOIN 가능하다.
ANSI문법 사용시 FROM절에 INNER 생략 가능하다.
별명은 양쪽 다 가지고 있지 않는 컬럼일 경우 생략가능하다.
예시
-- hr 스키마
-- ansi SQL (표준, MySQL도 가능)
-- 목적 : 부서명 얻기(d.department_name )
SELECT e.employee_id, e.first_name, e.department_id,
d.department_id, d.department_name
FROM employees e INNER JOIN departments d
ON e.department_id = d.department_id; -- 연결
-- oracle (위와 결과값이 같음)
SELECT e.employee_id, e.first_name, e.department_id,
d.department_id, d.department_name
FROM employees e, departments d
WHERE e.department_id = d.department_id; -- 같을때 연결하라
-- 목적 : JOB_ID == IT_PROG 업무명을 꺼내고 싶다
-- 데이터를 가지고 가서 맞춰보고 상대방의 정보를 가져올 수 있다.
SELECT e.employee_id, e.first_name, e.job_id,
j.job_id, j.job_title
FROM employees e, jobs j
WHERE e.job_id = j.job_id
AND e.job_id = 'IT_PROG';
-- 3개 테이블을 조인
-- NULL은 JOIN 불가!
SELECT e.employee_id, e.first_name,
d.department_name , j.job_title
FROM employees e, departments d, jobs j
WHERE e.department_id = d.department_id
AND e.job_id = j.job_id
AND e.employee_id = 101;
cross join : 2개의 테이블을 아무 조건없이 연결시키는 방법(ALL JOIN)
참고
실행시 1번테이블 * 2번테이블 결과값을 가져온다.
거의 사용하지 않는다.
예시
-- ansi
SELECT e.employee_id, e.first_name, e.department_id,
d.department_id, d.department_name
FROM employees e CROSS JOIN departments d;
-- oracle
SELECT e.employee_id, e.first_name, e.department_id,
d.department_id, d.department_name
FROM employees e, departments d;
full outer join :기준테이블과 대상 테이블에 매칭하는 필드값이 있는 경우모든 필드값으로테이블을 만들어서 데이터를 검색하는 방법
참고
data 전체를 뽑을 때 (간혹 사용)
결과값 : left outer join + right outer join
예시
-- ansi
SELECT e.employee_id, e.first_name, e.department_id,
d.department_id, d.department_name
FROM employees e FULL OUTER JOIN departments d
ON e.department_id = d.department_id;
/* oracle : 결론적으론 안됨 == error.
SELECT e.employee_id, e.first_name, e.department_id,
d.department_id, d.department_name
FROM employees e, departments d
WHERE e.department_id(+) = d.department_id(+); -- left
*/
-- 굳이 사용하겠다면 UNION 사용.
SELECT e.employee_id, e.first_name, e.department_id,
d.department_id, d.department_name
FROM employees e, departments d
WHERE e.department_id = d.department_id(+) -- left join
UNION
SELECT e.employee_id, e.first_name, e.department_id,
d.department_id, d.department_name
FROM employees e, departments d
WHERE e.department_id(+) = d.department_id; -- right join
-- e.department_id, d.department_id null 가져와라
-- ansi
SELECT e.employee_id, e.first_name, e.department_id,
d.department_id, d.department_name
FROM employees e FULL OUTER JOIN departments d
ON e.department_id = d.department_id
WHERE e.department_id IS NULL
OR d.department_id IS NULL;
-- oracle
SELECT e.employee_id, e.first_name, e.department_id,
d.department_id, d.department_name
FROM employees e, departments d
WHERE e.department_id = d.department_id(+)
AND e.department_id IS NULL
UNION
SELECT e.employee_id, e.first_name, e.department_id,
d.department_id, d.department_name
FROM employees e, departments d
WHERE e.department_id(+) = d.department_id
AND e.department_id IS NULL;
outer(외부) join : 기준테이블과 대상 테이블에 매칭하는 필드값이 있는 경우동일한 필드값이 없는 행도 검색하는 방법
left join(leftouter join) : 좌측테이블(기준 테이블)의 모든 필드값을 가져온다.
참고
실행시 e.department_id의 null의 값도 가져오게 된다.
예시
-- ansi
SELECT e.employee_id, e.first_name, e.department_id,
d.department_id, d.department_name
FROM employees e LEFT OUTER JOIN departments d
ON e.department_id = d.department_id;
-- oracle
SELECT e.employee_id, e.first_name, e.department_id,
d.department_id, d.department_name
FROM employees e, departments d
WHERE e.department_id = d.department_id(+);
-- 차집합 (e.department_id의 NULL을 가져와라)
SELECT e.employee_id, e.first_name, e.department_id,
d.department_id, d.department_name
FROM employees e, departments d
WHERE e.department_id = d.department_id(+)
AND e.department_id IS NULL;
right join(right outer join) : 우측 테이블(대상 테이블)의 모든 필드값을 가져온다.
참고
실행시 d.department_id의 null의 값도 가져오게 된다.
예시
-- ansi
SELECT e.employee_id, e.first_name, e.department_id,
d.department_id, d.department_name
FROM employees e RIGHT OUTER JOIN departments d
ON e.department_id = d.department_id;
-- oracle
SELECT e.employee_id, e.first_name, e.department_id,
d.department_id, d.department_name
FROM employees e, departments d
WHERE e.department_id(+) = d.department_id;
-- 차집합 (d.department_id NULL을 가져와라)
SELECT e.employee_id, e.first_name, e.department_id,
d.department_id, d.department_name
FROM employees e, departments d
WHERE e.department_id(+) = d.department_id
AND e.department_id IS NULL;
self join : 자기 자신과 join 한다.
참고
테이블 내 동일한 값이 다른 의미를 가지는 즉, 다른 컬럼에 존재하는 경우
예시
SELECT emp.employee_id, emp.first_name, emp.manager_id,
mgr.employee_id, mgr.first_name
FROM employees emp, employees mgr -- emp:사원, mgr:상사
WHERE emp.manager_id = mgr.employee_id;
-- null값까지 뽑기(self join + left outer join)
SELECT emp.employee_id, emp.first_name, emp.manager_id,
mgr.employee_id, mgr.first_name
FROM employees emp, employees mgr -- emp:사원, mgr:상사
WHERE emp.manager_id = mgr.employee_id(+);
-- scott 스키마
-- ASC : 올림차순
SELECT ename, sal FROM emp
ORDER BY sal ASC;
-- DESC : 내림차순
SELECT ename, sal FROM emp
ORDER BY sal DESC;
-- NULL 먼저 나오도록 하는법
SELECT ename, comm FROM emp
ORDER BY comm NULLS FIRST;
-- NULL 나중에 나오도록 하는법
SELECT ename, comm FROM emp
ORDER BY comm NULLS LAST;
-- 위와 동일 : NULLS LAST = default 값
SELECT ename, comm FROM emp
ORDER BY comm;
-- hr 스키마
-- 두가지 정렬 가능
SELECT employee_id, job_id, salary FROM employees
ORDER BY job_id ASC, salary DESC;
GROUP BY : 통계를 내기 위한 그룹화
형식
SELECT 컬럼명
FROM 테이블명
WHERE 조건식
GROUP BY 필드명1, 필드명2,.. 필드명n
HAVING 그룹 내 조건식;
참고
GROUP FUNCTION : COUNT() , SUM(), AVG(), MAX(), MIN()
예시
-- hr 스키마
-- COUNT : 얼마나 있느냐?
SELECT COUNT(salary) FROM employees
WHERE job_id = 'IT_PROG';
SELECT COUNT(salary), COUNT(*), SUM(salary), AVG(salary), MAX(salary), MIN(salary)
FROM employees
WHERE job_id = 'IT_PROG';
SELECT job_id
FROM employees
GROUP BY job_id
ORDER BY job_id;
/* 묶은 다음에는 일반 컬럼은 사용할 수 없다.
SELECT job_id, first_name
FROM employees
GROUP BY job_id
ORDER BY job_id;
*/
SELECT job_id, COUNT(*), SUM(salary), AVG(salary)
FROM employees
GROUP BY job_id
ORDER BY job_id;
-- 업무별로 급여의 합계가 100000이상인 업무만 출력하라.
-- 1. GROUP 2. HAVING
SELECT job_id, SUM(salary)
FROM employees
GROUP BY job_id
HAVING SUM(salary) >= 100000;
-- 급여가 5000이상 받는 사원으로 합계를 내서 업무로 그룹화하여
-- 급여의 합계가 20000을 초과하는 업무명을 구하라
-- 1. WHERE절 2. GROUP 3. HAVING 4. ORDER
SELECT job_id, SUM(salary) AS 합계
FROM employees
WHERE salary >= 5000
GROUP BY job_id
HAVING SUM(salary) > 20000
ORDER BY 합계 DESC;
-- hr 스키마
-- 이름 -> Julia
SELECT first_name, last_name FROM employees WHERE first_name = 'Julia';
-- 급여가 $9000 이상인 사원
SELECT first_name, salary FROM employees WHERE salary >= 9000;
-- 이름이 Shanta 보다 큰 이름 (이름도 비교가능)
SELECT first_name FROM employees WHERE first_name > 'Shanta';
-- 이름의 첫 스팰링이 J보다 큰 이름
SELECT first_name FROM employees WHERE first_name >= 'J';
-- 2007년 12월 31일 이후에 입사한 사원을 출력
-- 날짜 형식 비교시 날짜 -> '07/12/31' 이런식으로 써줘야 한다.
SELECT first_name, hire_date FROM employees WHERE hire_date > '07/12/31';
-- TO_DATE -> DATE -> String으로 변환
SELECT first_name, hire_date FROM employees WHERE hire_date > TO_DATE( '071231', 'yymmdd');
IS NULL( = NULL ), IS NOT NULL( != NULL ) : 값이 없는 상태 검색하기
형식
SELECT 컬럼명 FROM 테이블명 WHERE 컬럼명 IS NULL;
SELECT 컬럼명 FROM 테이블명 WHERE 컬럼명 IS NOT NULL;
예시
-- 매니저가 없는 사원
SELECT first_name FROM employees WHERE manager_id IS NULL;
-- = , '' 사용할 수 없다!!!
-- SELECT first_name FROM employees WHERE manager_id = NULL;
-- SELECT first_name FROM employees WHERE manager_id = '';
-- 매니저가 있는 사원
SELECT first_name FROM employees WHERE manager_id IS NOT NULL;
AND : 모두 만족하면 검색하기
형식
SELECT 컬럼명 FROM 테이블명 WHERE 컬럼명 = 검색값 AND 컬럼명 = 검색값;
예시
-- 이름 John, 월급은 5000이상
SELECT first_name, salary FROM employees WHERE first_name = 'John' AND salary >= 5000;
-- 입사일자가 06/01/01 ~ 06/12/31 사이인 사원
SELECT first_name, hire_date FROM employees
WHERE hire_date >= '06/01/01' AND hire_date <= '06/12/31';
OR : 하나라도 만족하면 검색하기
형식
SELECT 컬럼명 FROM 테이블명 WHERE 컬럼명 = 검색값 OR컬럼명 = 검색값;
예시
-- 이름이 Shanta이거나 Vollman인 사원 검색
SELECT first_name FROM employees WHERE first_name = 'Shanta' OR first_name = 'Vollman';
IN : 여러 데이터로 검색하기
형식
SELECT 컬럼명 FROM 테이블명 WHERE 컬럼명 IN (검색값, 검색값);
SELECT 컬럼명 FROM 테이블명 WHERE 컬럼명 NOT IN (검색값, 검색값);
예시
-- 급여가 8000, 3200, 6000 인 직원들
SELECT first_name, salary FROM employees WHERE salary IN (8000, 3200, 6000);
-- 급여가 8000, 3200, 6000 아닌 직원들
SELECT first_name, salary FROM employees WHERE salary NOT IN (8000, 3200, 6000);
ANY : 여러 데이터로 검색하기(=OR, =IN)
형식
SELECT 컬럼명 FROM 테이블명 WHERE 컬럼명 = ANY(검색값, 검색값);
예시
-- 급여가 8000, 3200, 6000인 직원들
SELECT first_name, salary FROM employees WHERE salary = ANY(8000, 3200, 6000);
BETWEEN .. AND(범위 연산자) : 범위에 만족하면 검색하기
형식
SELECT 컬럼명 FROM 테이블명 WHERE 컬럼명 BETWEEN 검색값 AND검색값;
SELECT 컬럼명 FROM 테이블명 WHERE 컬럼명 NOT BETWEEN 검색값 AND 검색값;
예시
-- 월급이 3200에서 9000사이인 사원 검색
SELECT first_name, salary FROM employees -- WHERE salary >= 3200 AND salary <= 9000;
WHERE salary BETWEEN 3200 AND 9000; -- 위와 동일
-- 월급이 3200에서 9000사이인 사원을 제외한 사원 검색
SELECT first_name, salary FROM employees WHERE salary NOT BETWEEN 3200 AND 9000;
LIKE : 포함된 문자로 검색하기 ★★★★★
형식
SELECT 컬럼명 FROM 테이블명 WHERE 컬럼명 LIKE '%검색값&';
참고
'문자%' : 문자로 시작하는 값
'%문자' : 문자로 끝나는 값
'%문자%' : 문자가 포함된 값
'_' : 지정한 위치에 1자리 문자면 무엇이든 가능
예시
-- _ 한글자가 어떠한 문자든 허용
SELECT first_name FROM employees WHERE first_name LIKE 'G_ra_d';
-- % 글자수에 제한없이 모두 허용
SELECT first_name FROM employees WHERE first_name LIKE 'K%y';
-- 이름의 시작이 K인 이름 모두 허용
SELECT first_name FROM employees WHERE first_name LIKE 'K%';
-- a 들어있는 이름 모두 허용
SELECT first_name FROM employees WHERE first_name LIKE '%a%';