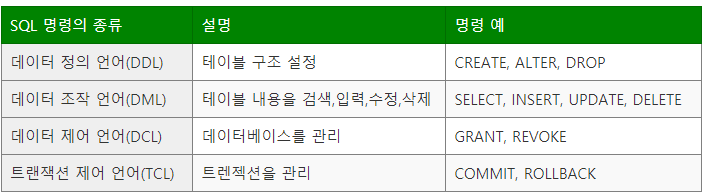
문제 1
운동부 TABLE을 작성하라.
TEAM : 팀 아이디, 지역, 팀 명, 개설 날짜, 전화번호, 홈페이지
PLAYER : 선수번호, 선수 명, 등록일, 포지션, 키, 팀 아이디
TEAM을 두 개만 등록합니다.
두 개의 TEAM에 선수를 각각 3명씩 등록(추가)합니다.
선수를 입력하면 그 선수의 팀 명과 전화번호, 홈페이지가 출력되도록 합니다.
예시
-- TEAM : 팀 아이디, 지역, 팀 명, 개설 날짜, 전화번호, 홈페이지
CREATE TABLE TB_TEAM(
TEAM_ID INTEGER,
LOCALS VARCHAR2(10) NOT NULL,
TEAM_NAME VARCHAR2(10) NOT NULL,
OPEN_DATE DATE NOT NULL,
PHONE_NUMBER VARCHAR2(15),
HOME_PAGE VARCHAR2(60),
CONSTRAINT PK_TEAM_T PRIMARY KEY(TEAM_ID)
);
-- TEAM을 두 개만 등록합니다.
INSERT INTO tb_team(TEAM_ID, LOCALS , TEAM_NAME, OPEN_DATE, PHONE_NUMBER, HOME_PAGE)
VALUES (100, '서울', '서울팀', '20/02/02', '010-123-4567', 'WWW.TJDNFXLA.COM');
INSERT INTO tb_team(TEAM_ID, LOCALS , TEAM_NAME, OPEN_DATE, PHONE_NUMBER)
VALUES (200, '부산', '부산팀', '19/05/01', '010-987-6543');
-- 부산팀 HOME_PAGE 데이터 추가
UPDATE tb_team
SET HOME_PAGE = 'WWW.QNTKSXLA.COM'
WHERE TEAM_ID = '200';
--PLAYER : 선수번호, 선수 명, 등록일, 포지션, 키, 팀 아이디
CREATE TABLE TB_PLAYER(
PLAYER_NO INTEGER,
PLAYER_NAME VARCHAR2(20) NOT NULL,
EMROLL_DATE DATE,
POSITIONS VARCHAR2(20) NOT NULL,
HEIGHT NUMBER(5,1),
TEAM_ID INTEGER,
CONSTRAINT FK_TEAM_P FOREIGN KEY(TEAM_ID)
REFERENCES TB_TEAM(TEAM_ID)
);
-- 두 개의 TEAM에 선수를 각각 3명씩 등록(추가)합니다.
INSERT INTO tb_player(PLAYER_NO, PLAYER_NAME, EMROLL_DATE, POSITIONS, HEIGHT, TEAM_ID)
VALUES (71, '일서울', '20/02/02', '투수', 175.33, 100);
INSERT INTO tb_player(PLAYER_NO, PLAYER_NAME, EMROLL_DATE, POSITIONS, TEAM_ID)
VALUES (72, '이서울', '20/03/09', '타자', 100);
INSERT INTO tb_player(PLAYER_NO, PLAYER_NAME, EMROLL_DATE, POSITIONS, HEIGHT, TEAM_ID)
VALUES (77, '삼서울', '20/04/21', '포수', 182.7, 100);
INSERT INTO tb_player(PLAYER_NO, PLAYER_NAME, EMROLL_DATE, POSITIONS, HEIGHT, TEAM_ID)
VALUES (31, '일부산', '20/01/01', '투수', 180.33, 200);
INSERT INTO tb_player(PLAYER_NO, PLAYER_NAME, EMROLL_DATE, POSITIONS, HEIGHT, TEAM_ID)
VALUES (32, '이부산', '20/07/01', '타자', 185.2, 200);
INSERT INTO tb_player(PLAYER_NO, PLAYER_NAME, EMROLL_DATE, POSITIONS, HEIGHT)
VALUES (33, '삼누구', TO_DATE('20190501', 'YYYYMMDD'), '포수', 179.1);
-- 선수를 입력하면 그 선수의 팀 명과 전화번호, 홈페이지가 출력되도록 합니다.
SELECT t.team_name, t.phone_number, t.home_page
FROM tb_team t, tb_player p
WHERE t.team_id = p.team_id
AND p.player_name = '이부산';
문제 2
온라인 마켓 TABLE을 작성하라.
PRODUCT(상품) : 상품번호, 상품명, 상품가격, 상품설명
CONSUMER(소비자) : 소비자 ID, 이름, 나이
CART(장바구니) : 장바구니 번호, 소비자 ID, 상품번호, 수량
상품 테이블에 상품을 등록합니다(개수는 원하는 데로).
소비자를 등록합니다.
소비자가 쇼핑한 상품을 추가합니다.
쇼핑한 상품을 출력합니다
예시
-- PRODUCT(상품) : 상품번호, 상품명, 상품가격, 상품설명
CREATE TABLE TB_PRODUCT(
"상품번호" INTEGER ,
"상품명" VARCHAR2(30) NOT NULL,
"상품가격" INTEGER NOT NULL,
"상품설명" VARCHAR2(50),
CONSTRAINT PK_PRODUCT_P PRIMARY KEY ("상품번호")
);
-- 상품 테이블에 상품을 등록합니다(개수는 원하는 데로).
INSERT INTO tb_product(상품번호, 상품명, 상품가격)
VALUES (1, '치약', 1000);
INSERT INTO tb_product(상품번호, 상품명, 상품가격, 상품설명)
VALUES (2, '칫솔', 1000, 'LG');
INSERT INTO tb_product(상품번호, 상품명, 상품가격, 상품설명)
VALUES (3, '햇반', 900, '해태');
INSERT INTO tb_product(상품번호, 상품명, 상품가격)
VALUES (4, '과자', 1500);
INSERT INTO tb_product(상품번호, 상품명, 상품가격, 상품설명)
VALUES (5, '아이스크림', 400, '농심');
INSERT INTO tb_product(상품번호, 상품명, 상품가격, 상품설명)
VALUES (6, '간장', 4500, '해찬들');
INSERT INTO tb_product(상품번호, 상품명, 상품가격, 상품설명)
VALUES (7, '돼지고기', 10000, '국산');
INSERT INTO tb_product(상품번호, 상품명, 상품가격, 상품설명)
VALUES (8, '소고기', 15000, '호주산');
INSERT INTO tb_product(상품번호, 상품명, 상품가격)
VALUES (9, '대파', 4000);
INSERT INTO tb_product(상품번호, 상품명, 상품가격, 상품설명)
VALUES (10, '식용유', 3500, '해찬들');
-- CONSUMER(소비자) : 소비자 ID, 이름, 나이
CREATE TABLE TB_CONSUMER(
소비자_ID VARCHAR2(30),
이름 VARCHAR2(20) NOT NULL,
나이 INTEGER,
CONSTRAINT PK_CONSUMER_P PRIMARY KEY (소비자_ID)
);
-- 소비자를 등록합니다.
INSERT INTO tb_consumer (소비자_ID, 이름, 나이)
VALUES('1A', '일고객' , 35);
INSERT INTO tb_consumer (소비자_ID, 이름)
VALUES('2A', '이고객');
INSERT INTO tb_consumer (소비자_ID, 이름, 나이)
VALUES('3A', '삼고객' , 29);
INSERT INTO tb_consumer (소비자_ID, 이름)
VALUES('4A', '사고객');
-- CART(장바구니) : 장바구니 번호, 소비자 ID, 상품번호, 수량
CREATE TABLE TB_CART(
장바구니_NO INTEGER NOT NULL,
소비자_ID VARCHAR2(30) NOT NULL,
상품번호 INTEGER,
수량 INTEGER NOT NULL,
CONSTRAINT FK_CART_F1 FOREIGN KEY (소비자_ID)
REFERENCES TB_CONSUMER(소비자_ID),
CONSTRAINT FK_CART_F2 FOREIGN KEY (상품번호)
REFERENCES TB_PRODUCT(상품번호)
);
-- 소비자가 쇼핑한 상품을 추가합니다.
INSERT INTO tb_cart(장바구니_NO, 소비자_ID, 상품번호, 수량)
VALUES (1, '1A', 5, 10);
INSERT INTO tb_cart(장바구니_NO, 소비자_ID, 상품번호, 수량)
VALUES (2, '1A', 2, 2);
INSERT INTO tb_cart(장바구니_NO, 소비자_ID, 상품번호, 수량)
VALUES (3, '1A', 1, 1);
INSERT INTO tb_cart(장바구니_NO, 소비자_ID, 상품번호, 수량)
VALUES (4, '1A', 3, 10);
INSERT INTO tb_cart(장바구니_NO, 소비자_ID, 상품번호, 수량)
VALUES (5, '1A', 9, 1);
INSERT INTO tb_cart(장바구니_NO, 소비자_ID, 상품번호, 수량)
VALUES (6, '2A', 10, 1);
INSERT INTO tb_cart(장바구니_NO, 소비자_ID, 상품번호, 수량)
VALUES (7, '2A', 7, 1);
INSERT INTO tb_cart(장바구니_NO, 소비자_ID, 상품번호, 수량)
VALUES (8, '2A', 8, 1);
INSERT INTO tb_cart(장바구니_NO, 소비자_ID, 상품번호, 수량)
VALUES (9, '2A', 4, 4);
INSERT INTO tb_cart(장바구니_NO, 소비자_ID, 상품번호, 수량)
VALUES (10, '2A', 5, 5);
INSERT INTO tb_cart(장바구니_NO, 소비자_ID, 상품번호, 수량)
VALUES (11, '2A', 9, 1);
INSERT INTO tb_cart(장바구니_NO, 소비자_ID, 상품번호, 수량)
VALUES (12, '3A', 1, 1);
INSERT INTO tb_cart(장바구니_NO, 소비자_ID, 상품번호, 수량)
VALUES (13, '3A', 2, 2);
INSERT INTO tb_cart(장바구니_NO, 소비자_ID, 상품번호, 수량)
VALUES (14, '3A', 3, 1);
INSERT INTO tb_cart(장바구니_NO, 소비자_ID, 상품번호, 수량)
VALUES (15, '3A', 4, 1);
INSERT INTO tb_cart(장바구니_NO, 소비자_ID, 상품번호, 수량)
VALUES (16, '3A', 5, 1);
INSERT INTO tb_cart(장바구니_NO, 소비자_ID, 상품번호, 수량)
VALUES (17, '4A', 6, 2);
INSERT INTO tb_cart(장바구니_NO, 소비자_ID, 상품번호, 수량)
VALUES (18, '4A', 7, 1);
INSERT INTO tb_cart(장바구니_NO, 소비자_ID, 상품번호, 수량)
VALUES (19, '4A', 8, 5);
INSERT INTO tb_cart(장바구니_NO, 소비자_ID, 상품번호, 수량)
VALUES (20, '4A', 9, 6);
INSERT INTO tb_cart(장바구니_NO, 소비자_ID, 상품번호, 수량)
VALUES (21, '4A', 10, 1);
-- 쇼핑한 상품을 출력합니다
SELECT c2."이름", p."상품명"
FROM tb_cart c1, tb_consumer c2, tb_product p
WHERE c1."소비자_ID" = c2."소비자_ID"
AND c1."상품번호" = p."상품번호"
AND c1."소비자_ID" = '1A';
-- 일고객이 쓴 총액
SELECT c2."이름", sum(p.상품가격)
FROM tb_cart c1, tb_consumer c2, tb_product p
WHERE c1."소비자_ID" = c2."소비자_ID"
AND c1."상품번호" = p."상품번호"
GROUP BY c2."이름"
HAVING c2."이름" = '일고객';
'문제풀이 > Oracle SQL' 카테고리의 다른 글
| [Oracle DB SQL] 테이블 생성/시퀀스 연습문제 (0) | 2021.06.01 |
|---|---|
| [Oracle DB SQL] VIEW 연습문제 (0) | 2021.06.01 |
| [Oracle DB SQL] 테이블 생성/데이터 추가/데이터 삭제/데이터 수정 / 연습하기 (0) | 2021.05.31 |
| [Oracle DB SQL] scott Schema Sub Query 연습문제 (0) | 2021.05.31 |
| [Oracle DB SQL] hr Schema Sub Query 연습문제 (0) | 2021.05.31 |